La revue de l'AFL
Modèle de l'empan visuel en lecture
Nous reproduisons ici des extraits diffusés sur le serveur WEB du Minnesota Laboratory for Low-Vision Research (http://vision.psych.umn.edu/chips.html) présentant un état intermédiaire des recherches menées par Gordon Legge. Extraits qui sont par ailleurs la matière d'un article intitulé « Mr Chips : an Ideal-Observer Model of Reading » (Psychological Review, 1997, Vol. 104, n° 3, 524-553) dans lequel Legge et son équipe étudient les « empans visuels » dans le cas où le lecteur possède une vue normale et dans le cas contraire.
L'intérêt de cette recherche tient au fait que ses auteurs intègrent dans leur approche de l'activité de lecture des données visuelles, lexicales et oculomotrices supposées participer À l'intéraction entre les données de bas et de haut niveau. La simulation par « Mr Chips » combine ces différentes sources d'information dans la lecture de textes simples, avec un nombre minimum de saccades. Le comportement du modèle informatique et sa capacité À simuler les pertes de champ visuel (central ou périphérique) conduisent À réexaminer ce qui est dit des saccades oculaires dans la littérature scientifique et À émettre de nouvelles interprétations du fonctionnement humain.
But.
L'empan visuel en lecture est le nombre N de caractères adjacents À la vision centrale qui peuvent être reconnus. L'expérience prouve que l'empan visuel diminue jusqu'À atteindre la limite de l'acuité, quand le texte a un faible niveau de contraste, et dans quelques formes de vision limitée. Nous avons évalué les résultats en lecture comme étant fonction de la taille de l'empan visuel chez les sujets humains et pour un modèle d'observateur idéal appelé M. Chips.
Méthodes.
La tâche de M. Chips est de se déplacer dans le texte en un nombre minimum de saccades et d'identifier tous les mots. M. Chips dispose de deux sources d'informations :
1) les données visuelles, N lettres identifiables dans l'empan visuel (plus les informations sur la longueur des mots situés À la périphérie) ;
2) les données lexicales, les mots qui peuvent être utilisés et leur probabilité d'occurrence. (Legge, ARVO, 1992). La répartition des saccades chez M. Chips a été mesurée pour des empans visuels allant de 1 À 11 caractères, avec des lexiques réduits et importants (542 et 20 mots). Les résultats de M. Chips ont également été comparés avec une stratégie quasi idéale « purement visuelle » dans laquelle le lecteur avance dans le texte avec des saccades égales À l'empan visuel.
MODÈLE D'OBSERVATEUR IDÉAL
M. Chips est une simulation informatique du modèle d'observateur idéal. La tâche de M. Chips est de se déplacer de façon séquentielle dans un texte en un nombre minimum de saccades et d'identifier tous les mots sans erreur.
INFORMATIONS DISPONIBLES
* Informations lexicales
Nous avons étudié les conséquences de l'utilisation de deux lexiques différents sur les résultats de M. Chips. Un lexique comprenait les 542 mots les plus employés en anglais écrit et leur fréquence d'occurrence. Le second lexique était un sous-ensemble de 20 mots (ce qui sous-entend une bien meilleur connaissance du lexique utilisé, et donc une plus grande facilité d'anticipation) représentant une tentative de simulation de la restriction contextuelle en lecture.
* Informations visuelles
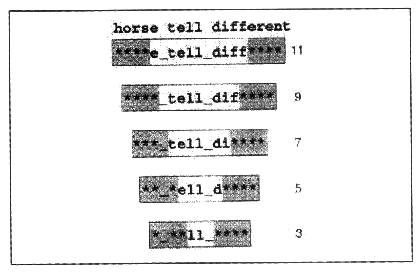
M. Chips examine le texte À l'aide d'une «rétine» comprenant deux régions d'informations visuelles : les zones facilement lisibles dans lesquelles les lettres peuvent être identifiées et les zones À difficilement lisibles (désignées par un fond gris) dans lesquelles les lettres (*) et les espaces (_) peuvent être distingués. Le texte en gris représente les mots qui ont bien été identifiés, alors que le texte en caractères gras représente le mot sur lequel M. Chips est encore en train de travailler.
Nous avons étudié l'influence d'une propriété de la « rétine » de M. Chips (figure 2)
* La taille de l'empan visuel, allant de 1 À 11 caractères
PRINCIPE D'OPTIMISATION
M. Chips détermine des saccades À partir du modèle suivant : « Obtenir des saccades qui minimisent l'incertitude À propos du mot qu'on est en train de lire. S'il y a une entrave, choisir la saccade qui déplace la rétine le plus vers la droite. »
MESURE DES RÉSULTATS
Nous avons utilisé la distribution des « saccades » effectuées par M. Chips pour calculer la taille d'une « saccade » moyenne.
RÉSULTATS POUR LES MODÈLES DE M. CHIPS
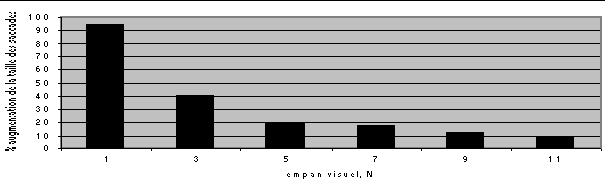
* Les résultats de M. Chips, qui utilise toutes les informations lexicales et visuelles disponibles, ont été comparés avec ceux d'un observateur purement visuel, qui n'utilise aucune information lexicale ni aucune information sur la longueur des mots. (figure 3)
RÉSULTATS POUR LES LEXIQUES DE M. CHIPS
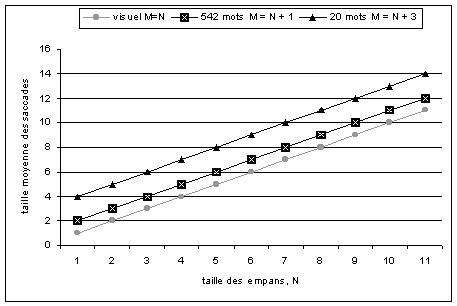
* Les résultats de M. Chips ont été étudiés en utilisant les lexiques de 542 et 20 mots. (Figure 4)
figure 4 : résultats pour le lexique de Mr Chips,
* Avec le lexique réduit (20 mots), la taille d'une saccade moyenne augmente d'au moins 2 caractères pour tous les empans visuels, de façon À obtenir M=N+3.
Ces expériences confirment d'autres observations réalisées par ailleurs, sur l'influence de la mobilisation lexicale sur la taille de l'empan au cours d'un point de fixations. Ce qui est appelé ici lexique réduit, constitué de 20 mots, amène une augmentation de la taille de l'empan visuel de deux mots par rapport À l'utilisation d'un lexique de 542 mots ; l'excellente connaissance du lexique de 20 mots est reliée À une grande augmentation de l'empan visuel.
CONCLUSIONS
* Pour M. Chips, la taille d'une saccade moyenne est linéairement liée À l'empan visuel. * L'utilisation des informations lexicales améliore les résultats en lecture (augmentation en pourcentage de la taille d'une saccade moyenne), avec une amélioration plus importante quand il y a un empan visuel réduit. À
T.S. KLITZ, G.E. LEGGE
Certains points appellent quelques commentaires :
1) On remarque que plus la taille de l'empan visuel augmente, moins les informations lexicales sont nécessaires pour augmenter la taille de l'empan. Cette observation rejoint les remarques que nous avions faites dans l'étude des mots de 10 lettres quand ils sont simulés par des silhouettes de lettres. Rappelons que plus on s'éloigne du point de fixation, plus les informations sont visuellement dégradées. Nous avions montré que plus la taille du mot augmentait, plus les informations graphiques suffisaient, même dégradées pour identifier un mot. « on peut observer que plus les mots sont longs, (donc plus ils échappent À l'information de l'empan visuel pour dépendre de l'empan de lecture), plus leur silhouettes suffit À les individualiser. » On peut observer que le remplacement des lettres dégradées par des * (les espaces par des _) n'est pas très fine. C'est pourquoi nous sommes actuellement en contact avec cette équipe de Legge pour remplacer ces croix par des représentations de lettres sur un gréement. Les résultats de ces expériences plus fines ne pourront que mieux faire comprendre le fonctionnement de cette vision dégradée.
2) Les quelques recherches menées sur la vision floue, périphérique de nature parafovéale sont également importantes pour la compréhension du phénomène. Elles tendent À montrer le traitement logographique des unités parafovéales traitées pendant la lecture. Nous reviendrons prochainement sur les mécanismes À l'oeuvre dans la vision périphérique dégradée (parafovéale), en présentant les recherches menées dans cette voie.
Texte traduit par Aline ESPERET
présenté par Denis FOUCAMBERT
Les actes de lecture n°60 décembre 1997
___________________
Modèle de l'empan visuel en lecture
Nous reproduisons ici des extraits diffusés sur le serveur WEB du Minnesota Laboratory for Low-Vision Research (http://vision.psych.umn.edu/chips.html) présentant un état intermédiaire des recherches menées par Gordon Legge. Extraits qui sont par ailleurs la matière d'un article intitulé « Mr Chips : an Ideal-Observer Model of Reading » (Psychological Review, 1997, Vol. 104, n° 3, 524-553) dans lequel Legge et son équipe étudient les « empans visuels » dans le cas où le lecteur possède une vue normale et dans le cas contraire.
L'intérêt de cette recherche tient au fait que ses auteurs intègrent dans leur approche de l'activité de lecture des données visuelles, lexicales et oculomotrices supposées participer À l'intéraction entre les données de bas et de haut niveau. La simulation par « Mr Chips » combine ces différentes sources d'information dans la lecture de textes simples, avec un nombre minimum de saccades. Le comportement du modèle informatique et sa capacité À simuler les pertes de champ visuel (central ou périphérique) conduisent À réexaminer ce qui est dit des saccades oculaires dans la littérature scientifique et À émettre de nouvelles interprétations du fonctionnement humain.
But.
L'empan visuel en lecture est le nombre N de caractères adjacents À la vision centrale qui peuvent être reconnus. L'expérience prouve que l'empan visuel diminue jusqu'À atteindre la limite de l'acuité, quand le texte a un faible niveau de contraste, et dans quelques formes de vision limitée. Nous avons évalué les résultats en lecture comme étant fonction de la taille de l'empan visuel chez les sujets humains et pour un modèle d'observateur idéal appelé M. Chips.
Méthodes.
La tâche de M. Chips est de se déplacer dans le texte en un nombre minimum de saccades et d'identifier tous les mots. M. Chips dispose de deux sources d'informations :
1) les données visuelles, N lettres identifiables dans l'empan visuel (plus les informations sur la longueur des mots situés À la périphérie) ;
2) les données lexicales, les mots qui peuvent être utilisés et leur probabilité d'occurrence. (Legge, ARVO, 1992). La répartition des saccades chez M. Chips a été mesurée pour des empans visuels allant de 1 À 11 caractères, avec des lexiques réduits et importants (542 et 20 mots). Les résultats de M. Chips ont également été comparés avec une stratégie quasi idéale « purement visuelle » dans laquelle le lecteur avance dans le texte avec des saccades égales À l'empan visuel.
MODÈLE D'OBSERVATEUR IDÉAL
M. Chips est une simulation informatique du modèle d'observateur idéal. La tâche de M. Chips est de se déplacer de façon séquentielle dans un texte en un nombre minimum de saccades et d'identifier tous les mots sans erreur.
INFORMATIONS DISPONIBLES
* Informations lexicales
Nous avons étudié les conséquences de l'utilisation de deux lexiques différents sur les résultats de M. Chips. Un lexique comprenait les 542 mots les plus employés en anglais écrit et leur fréquence d'occurrence. Le second lexique était un sous-ensemble de 20 mots (ce qui sous-entend une bien meilleur connaissance du lexique utilisé, et donc une plus grande facilité d'anticipation) représentant une tentative de simulation de la restriction contextuelle en lecture.
* Informations visuelles

|
M. Chips examine le texte À l'aide d'une «rétine» comprenant deux régions d'informations visuelles : les zones facilement lisibles dans lesquelles les lettres peuvent être identifiées et les zones À difficilement lisibles (désignées par un fond gris) dans lesquelles les lettres (*) et les espaces (_) peuvent être distingués. Le texte en gris représente les mots qui ont bien été identifiés, alors que le texte en caractères gras représente le mot sur lequel M. Chips est encore en train de travailler.
Nous avons étudié l'influence d'une propriété de la « rétine » de M. Chips (figure 2)
* La taille de l'empan visuel, allant de 1 À 11 caractères
|
PRINCIPE D'OPTIMISATION
M. Chips détermine des saccades À partir du modèle suivant : « Obtenir des saccades qui minimisent l'incertitude À propos du mot qu'on est en train de lire. S'il y a une entrave, choisir la saccade qui déplace la rétine le plus vers la droite. »
MESURE DES RÉSULTATS
Nous avons utilisé la distribution des « saccades » effectuées par M. Chips pour calculer la taille d'une « saccade » moyenne.
RÉSULTATS POUR LES MODÈLES DE M. CHIPS
* Les résultats de M. Chips, qui utilise toutes les informations lexicales et visuelles disponibles, ont été comparés avec ceux d'un observateur purement visuel, qui n'utilise aucune information lexicale ni aucune information sur la longueur des mots. (figure 3)
|
RÉSULTATS POUR LES LEXIQUES DE M. CHIPS
* Les résultats de M. Chips ont été étudiés en utilisant les lexiques de 542 et 20 mots. (Figure 4)
|
figure 4 : résultats pour le lexique de Mr Chips,
* Avec le lexique réduit (20 mots), la taille d'une saccade moyenne augmente d'au moins 2 caractères pour tous les empans visuels, de façon À obtenir M=N+3.
Ces expériences confirment d'autres observations réalisées par ailleurs, sur l'influence de la mobilisation lexicale sur la taille de l'empan au cours d'un point de fixations. Ce qui est appelé ici lexique réduit, constitué de 20 mots, amène une augmentation de la taille de l'empan visuel de deux mots par rapport À l'utilisation d'un lexique de 542 mots ; l'excellente connaissance du lexique de 20 mots est reliée À une grande augmentation de l'empan visuel.
CONCLUSIONS
* Pour M. Chips, la taille d'une saccade moyenne est linéairement liée À l'empan visuel. * L'utilisation des informations lexicales améliore les résultats en lecture (augmentation en pourcentage de la taille d'une saccade moyenne), avec une amélioration plus importante quand il y a un empan visuel réduit. À
T.S. KLITZ, G.E. LEGGE
Certains points appellent quelques commentaires :
1) On remarque que plus la taille de l'empan visuel augmente, moins les informations lexicales sont nécessaires pour augmenter la taille de l'empan. Cette observation rejoint les remarques que nous avions faites dans l'étude des mots de 10 lettres quand ils sont simulés par des silhouettes de lettres. Rappelons que plus on s'éloigne du point de fixation, plus les informations sont visuellement dégradées. Nous avions montré que plus la taille du mot augmentait, plus les informations graphiques suffisaient, même dégradées pour identifier un mot. « on peut observer que plus les mots sont longs, (donc plus ils échappent À l'information de l'empan visuel pour dépendre de l'empan de lecture), plus leur silhouettes suffit À les individualiser. » On peut observer que le remplacement des lettres dégradées par des * (les espaces par des _) n'est pas très fine. C'est pourquoi nous sommes actuellement en contact avec cette équipe de Legge pour remplacer ces croix par des représentations de lettres sur un gréement. Les résultats de ces expériences plus fines ne pourront que mieux faire comprendre le fonctionnement de cette vision dégradée.
2) Les quelques recherches menées sur la vision floue, périphérique de nature parafovéale sont également importantes pour la compréhension du phénomène. Elles tendent À montrer le traitement logographique des unités parafovéales traitées pendant la lecture. Nous reviendrons prochainement sur les mécanismes À l'oeuvre dans la vision périphérique dégradée (parafovéale), en présentant les recherches menées dans cette voie.
Texte traduit par Aline ESPERET
présenté par Denis FOUCAMBERT